
Economics of IoT – Lessons for service providers and enterprises

Owen Rogers of 451 Research
Many organisations have moved their infrastructure to a public cloud environment,and now many are using cloud services to manage the Internet of Things.
In fact, more than two-thirds of enterprises use edge and near-edge compute assets for IoT analytics, machine and other IoT data. To accommodate this data, leading hyperscale cloud providers like AWS, Google and Microsoft have cloud IoT offerings available for enterprise use on a pay-as-you-go basis.
Earlier this year, the Digital Economics and IoT analysts at 451 Research detected a cut in Azure’s IoT pricing of about 50%. This substantial change led the analysts to ask, “Was there a way to find out which of the hyperscaler cloud IoT platforms (AWS, Google and Microsoft) was cheapest?”
Essentially, the team wanted to understand which cost parameters – such as the average size of the message, the number of messages and the number of registry updates – had the biggest impact on the choice of cheapest provider. But the team’s ultimate objective was to understand which provider, overall, was most likely to be the cheapest.
After identifying nine pricing parameters that could have the most impact on cost, the analysts implemented a machine learning strategy and constructed a Python simulation to automatically compare the US pricing models for AWS, Google and Microsoft.
With a sample size of 10,000,000 simulations, 451 Research analysts found Azure and AWS to be cost-beneficial in some circumstances (shown in decision tree diagram). Microsoft generally seemed to be cheaper at scale, whereas AWS is cheaper in most enterprise use cases today. However, Google was not found to be cheapest in any of the simulations conducted.
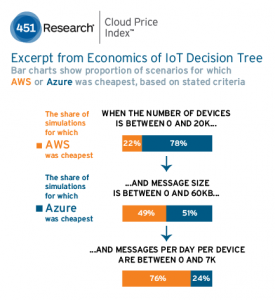
Their experience in trying to find an answer to this economics-of-IoT conundrum led to two conclusions. First, the accessibility of machine learning as a service provided them with a capability for discoveries that we simply didn’t have before.
However, while much of the complexity of machine learning was abstracted, a depth of knowledge was still needed to unravel the complexities of the pricing model such that machine learning could be used. In other words, for enterprises, having experts in machine learning isn’t enough.
Experts in the context of the data are needed to make machine learning viable, which means giving employees a grounding in these techniques so that these experts can take advantage of the tools, and of the machine learning experts. Vertical specialisms have a big role to play.
The second conclusion was that, even when the pricing model is simplified, nuances add complexity, and their impact is often unclear. Today, the fact of the matter is that if an enterprise wants to confidently understand its cloud bill, it often needs to manually calculate the cost.
This simply isn’t practical, and most cloud consumers don’t understand exactly what they’re paying for.This isn’t the ‘just like electricity’ utility cloud – this is a complex puzzle where few, if any, cloud consumers really have a handle on their expenditure.
Both conclusions provide opportunities for service providers: to reduce complexity and broker across platforms to save your customers money and headaches, and to enable and simplify access to machine learning services to allow non experts to take advantage.
The author of this blog is Owen Rogers, research director – Digital Economics Unit
Comment on this article below or via Twitter @IoTGN